RegEx Introduction
A regular expression is a sequence of characters that define a search pattern.
1. What exactly is a Regular Expression?
A regular expression, often called a pattern, is an expression used to specify a set of strings required for a particular purpose.
-
A simple way to specify a finite set of strings is to list its elements or members.
For example{file, file1, file2}. -
However, there are often more concise ways to specify the desired set of strings.
For example, the set{file, file1, file2}can be specified by the patternfile(1|2)?.
We say that this pattern matches each of the three strings. Wanna check?
In most formalisms, if there exists at least one regular expression that matches a particular set then there exists an infinite number of other regular expressions that also match it, i.e. the specification is not unique.
For example, the string set {file, file1, file2} can also be specified by the pattern file\d?.
2. The math of Regular Expressions
-
The concept of Regular Expressions originated from Regular Languages.
-
Regular Expressions describe Regular Languages in Formal Language Theory.
*Formal Language Theory: In mathematics, computer science, and linguistics, a formal language* consists of words whose letters are taken from an alphabet and are well-formed according to a specific set of rules. The field of formal language theory studies primarily the purely syntactical aspects of such languages—that is, their internal structural patterns.
*Regular Languages: A regular language is a category of formal languages* which can be expressed using a regular expression.
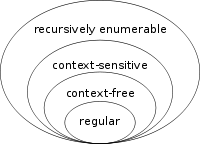
- Note: Today, many regular expressions engines provided by modern programming languages are augmented with features that allow recognition of languages that cannot be expressed by a classic regular expression!
3. Uses of Regular Expressions
Some important usages of regular expressions are:
-
Check if an input honors a given pattern; for example, we can check whether a value entered in a HTML formulary is a valid e-mail address
-
Look for a pattern appearance in a piece of text; for example, check if either the word “color” or the word “colour” appears in a document with just one scan
-
Extract specific portions of a text; for example, extract the postal code of an address
-
Replace portions of text; for example, change any appearance of “color” or “colour” with “red”
-
Split a larger text into smaller pieces, for example, splitting a text by any appearance of the dot, comma, or newline characters
4. A brief history of Regular Expressions
The story begins with a neuroscientist and a logician who together tried to understand how the human brain could produce complex patterns using simple cells that are bound together.
-
In 1943, neurophysiologists *Warren McCulloch* and *Walter Pitts* published *“A logical calculus of the ideas immanent in nervous activity”*. This paper not only represented the beginning of the regular expressions, but also proposed the first mathematical model of a neural network.
-
In 1956, *Stephen Kleene* wrote the paper *“Representation of events in nerve nets and finite automata”, where he coined the terms regular sets* and regular expressions and presented a simple algebra.
-
In 1968, the Unix pioneer *Ken Thompson* took Kleene’s work and extended it, publishing his studies in the paper *“Regular Expression Search Algorithm”. Ken Thompson’s work didn’t end in just writing a paper. He also implemented Kleene’s notation in the editor QED. The aim was that the user could do advanced pattern matching in text files. The same feature appeared later on in the editor ed*.
To search for a Regular Expression in ed you wrote
g/<regular expression>/pThe letter g meant global search and p meant print the result. The command —g/re/p— resulted in the standalone program grep, released in the fourth edition of Unix 1973.
However, grep didn’t have a complete implementation of regular expressions.
-
In 1979, *Alfred Aho* developed *egrep (extended grep)* in the seventh edition of Unix. The program egrep translated any regular expressions to a corresponding DFA.
-
In 1987, *Larry Wall* created the scripting language *Perl. Regular Expressions are seamlessly integrated in Perl, even with its own literals. Hence, Perl pushed the regular expressions to the mainstream. The implementation in Perl went forward and added many modifications to the original regular expression syntax, creating the so-called Perl flavor*.
Some other worth mentioning milestones
-
The IEEE thought their POSIX standard has tried to standardize and give better Unicode support to the regular expression syntax and behaviors. This is called the *POSIX flavor* of the regular expressions.
-
In late 1980s, *Henry Spencer* wrote *“regex”*, a widely used software library for regular expressions in C programming langauge.
Here is a brief timeline to summarize…

Regex today
-
It was the rise of the web that gave a big boost to the Perl implementation of regex, and that’s where we get the modern syntax of regular expressions today; it really comes from Perl.
Apache,C,C++,the .NET languages,Java,JavaScript,MySQL,PHP,Python,Rubyall of these are endeavoring to be Perl-compatible languages and programs. There’s also a library called thePCRElibrary that stands for Perl-Compatible Regular Expression library. -
Today, the standard Python module for regular expressions—
re—supports only Perl-style regular expressions. There is an effort to write a new regex module with better POSIX style support. This new module is intended to replace Python’sremodule implementation eventually.
5. Understanding the Regular Expression Syntax
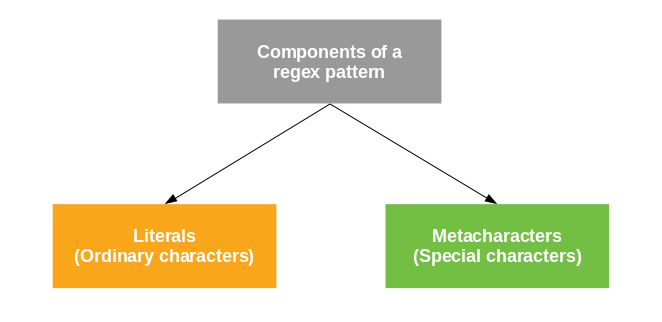
A regex pattern is a simple sequence of characters. The components of a regex pattern are:
-
literals (ordinary characters): these characters carry no special meaning and are processed as it is.
-
metacharacters (special characters): these characters carry a special meaning and processed in some special way.
Let’s start with a simple example.
Consider that we have got the list of several filenames in a folder.
file1.xml
file1.txt
file2.txt
file15.xml
file5.docx
file60.txt
file5.txt
And we want to filter out only those filenames which follow a specific pattern, i.e. file<one or more digits>.txt.
Let’s try to do this on an online tool to learn, build, & test Regular Expressions (RegEx / RegExp), RegExr.
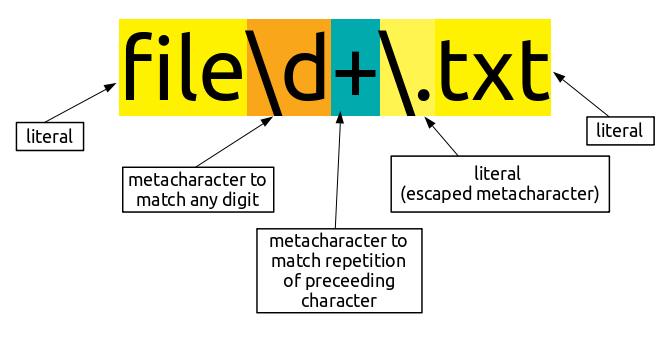
So, the regular expression we need here is:
file\d+\.txt
This expression can be understood as follows:
-
fileis a substring of literals which are matched with the input as it is. -
\dis a metacharacter which instructs the software to match this position with a digit (0-9). -
+is also a metacharacter which instructs the software to match one or more iterations of the preceeding character (\din this case) -
\.is a literal..is a metacharacter but we want to use it as a literal in this case. Hence, we escape it using\character. -
txtis a substring of literals which are matched with the input as it is.


Getting started with RegEx in Python
The re module provides an interface to the regular expression engine, allowing you to compile regular expressions into objects and then perform matches with them.
import re
1. Compiling Regular Expressions
Regular expressions are compiled into Pattern objects, which have methods for various operations such as searching for pattern matches or performing string substitutions.
re.compile(pattern, flags=0)
Compile a regular expression pattern, returning a pattern object.
- The regular expression is passed to
re.compile()as a string.
Regular expressions are handled as strings because regular expressions aren’t part of the core Python language, and no special syntax was created for expressing them.
Regular expression patterns are compiled into a series of bytecodes which are then executed by a matching engine written in C.
pattern = re.compile("hello")
pattern
re.compile(r'hello', re.UNICODE)
re.compile()also accepts an optionalflagsargument, used to enable various special features and syntax variations. More about flags
In the example below, we use the flag re.I (short for re.IGNORECASE) to ignore letter case in the regex pattern.
pattern = re.compile("hello", flags=re.I)
pattern
re.compile(r'hello', re.IGNORECASE|re.UNICODE)
2. Performing Matches
So, we have created a Pattern object representing a compiled regular expression using re.compile() method.
Pattern objects have several methods and attributes.
Here is the list of different methods used for performing matches:
| Method/Attribute | Purpose |
|---|---|
| match() | Determine if the RE matches at the beginning of the string. |
| search() | Scan through a string, looking for any location where this RE matches. |
| findall() | Find all substrings where the RE matches, and returns them as a list. |
| finditer() | Find all substrings where the RE matches, and returns them as an iterator. |
Let us go through them one by one:
match(string[, pos[, endpos]])
A match is checked only at the beginning (by default).
Checking starts from
posindex of the string. (default is 0)Checking is done until
endposindex of string.endposis set as a very large integer (by default).Returns
Noneif no match found.If a match is found, a
Matchobject is returned, containing information about the match: where it starts and ends, the substring it matched, and more.
pattern = re.compile("hello")
match = pattern.match("hello world")
match.span()
(0, 5)
match.start()
0
match.end()
5
pattern.match("say hello", pos=4) is None
False
pattern.match("hello", endpos=4) is None
True
search(string[, pos[, endpos]])
A match is checked throughtout the string.
Same behaviour of
posandendposas thematch()function.Returns
Noneif no match found.If a match is found, a
Matchobject is returned.
pattern.search("say hello")
<_sre.SRE_Match object; span=(4, 9), match='hello'>
pattern.search("say hello hello")
<_sre.SRE_Match object; span=(4, 9), match='hello'>
findall(string[, pos[, endpos]])
Finds all non-overlapping substrings where the match is found, and returns them as a list.
Same behaviour of
posandendposas thematch()andsearch()function.
pattern.findall("say hello hello")
['hello', 'hello']
finditer(string[, pos[, endpos]])
Finds all non-overlapping substrings where the match is found, and returns them as an iterator of the
Matchobjects.Same behaviour of
posandendposas thematch(),search()andfindall()function.
matches = pattern.finditer("say hello hello")
for match in matches:
print(match.span())
(4, 9) (10, 15)
from utils import highlight_regex_matches
highlight_regex_matches(pattern, "say hello hello")
say hello hello
By now, you must have noticed that
match(),search()andfinditer()returnMatchobject(s) where asfindall()returns a list of strings.
Note:
It is not mandatory to create a Pattern object explicitly using re.compile() method in order to perform a regex operation.
You can direclty use the module level functions such as:
re.match(pattern, string, flags=0)re.search(pattern, string, flags=0)re.findall(pattern, string, flags=0)re.finditer(pattern, string, flags=0)
and so on.
In a module level function, you can simply pass a string as your regex pattern as shown in the examples below.
re.match("hello", "hello")
<_sre.SRE_Match object; span=(0, 5), match='hello'>
re.findall("hello", "say hello hello")
['hello', 'hello']
Important Example
Consider the example below:
txt = "This book costs $15."
Search for the pattern $15.
pattern = re.compile("$15")
pattern.search(txt)
No match found. Why?
$ is a metacharacter and has a special meaning for regex engine. Here, we want to treat it like a literal.
In order to treat a metacharacter like a literal, you need to escape it using \ character.
pattern = re.compile("\$15")
pattern.search(txt)
<_sre.SRE_Match object; span=(16, 19), match='$15'>
In regular expressions, there are twelve metacharacters that should be escaped if they are to be used with their literal meaning:
- Backslash
\ - Caret
^ - Dollar sign
$ - Dot
. - Pipe symbol
| - Question mark
? - Asterisk
* - Plus sign
+ - Opening parenthesis
( - Closing parenthesis
) - Opening square bracket
[ - The opening curly brace
{
